> For the complete documentation index, see [llms.txt](https://extensityai.gitbook.io/symbolicai/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://extensityai.gitbook.io/symbolicai/features/contracts.md).
# Contracts
In SymbolicAI, the `@contract` decorator provides a powerful mechanism, inspired by Design by Contract (DbC) principles, to enhance the reliability and semantic correctness of `Expression` classes, especially those interacting with Large Language Models (LLMs). It allows you to define explicit pre-conditions, post-conditions, and intermediate processing steps, guiding the behavior of your classes and the underlying LLMs. The original post introducing this feature can be found [here](https://futurisold.github.io/2025-03-01-dbc/).
 ## Why Use Contracts?
Traditional software development often relies on testing to verify correctness after the fact. Contracts, however, encourage building correctness into the design itself. When working with LLMs, which are inherently probabilistic, ensuring that outputs are not only syntactically valid but also semantically meaningful and contextually appropriate is crucial.
Contracts in SymbolicAI help bridge this gap by:
1. **Enforcing Semantic Guarantees**: Beyond static type checking (which ensures structural validity), contracts allow you to define and validate what your `Expression`'s inputs and outputs *mean* in a given context.
2. **Guiding LLM Behavior**: The error messages raised by failed pre-conditions and post-conditions are used as corrective prompts, enabling the LLM to attempt self-correction. This turns validation failures into learning opportunities for the model.
3. **Proactive Structuring**: Designing a contract forces careful consideration of inputs, outputs, and invariants, shifting from reactive validation to proactive structuring of your logic.
4. **Improving Predictability and Reliability**: By setting clear expectations and validation steps, contracts make your AI components more predictable and less prone to unexpected or undesirable outputs (like hallucinations).
5. **Enhancing Composability**: Clear contracts at the interface level allow different components (potentially powered by different LLMs or even rule-based systems) to interoperate reliably, as long as they satisfy the agreed-upon contractual obligations.
## What is a `@contract` in SymbolicAI?
The `@contract` is a class decorator that you apply to your custom classes inheriting from `symai.Expression`. It augments your class, particularly its `forward` method, by wrapping it with a validation and execution pipeline.
Key characteristics:
* **Operates on LLMDataModel or Python types**: Inputs to and outputs from the core contract-validated logic can be instances of `symai.models.LLMDataModel` (extending Pydantic's `BaseModel`) or native Python types (e.g., `str`, `int`, `list[int]`, `dict[str, int]`, `Optional[...]`, `Union[...]`). Dynamic type annotation automatically wraps primitive or complex Python types into internal LLMDataModel wrappers (with a single `value` field) for validation and unwrapping, reducing verbosity compared to defining full LLMDataModel classes for simple use cases.
* **User-Defined Conditions**: You define the contract's terms by implementing specific methods: `pre` (pre-conditions), `act` (optional intermediate action), and `post` (post-conditions), along with a `prompt` property.
* **Fallback Mechanism**: A contract never entirely prevents the execution of your class's original `forward` method. If contract validation fails (even after remedies), your `forward` method is still called (typically with the original, unvalidated input, if the failure happened before `act`, or the `act`-modified input if failure was in `post`), allowing you to implement fallback logic or return a default, type-compliant object.
* **State and Results**: The decorator adds attributes to your class instance:
* `self.contract_successful` (bool): Indicates if all contract validations (including remedies) passed.
* `self.contract_result` (Any): Holds the validated and potentially remedied output if successful; otherwise, it might be `None` or an intermediate value if an error occurred before `_validate_output` completed successfully.
* `self.contract_perf_stats()` (method): Returns a dictionary with performance metrics for various stages of the contract execution.
## Core Components of a Contracted Class
To use the `@contract` decorator, you'll define several key components within your `Expression` subclass:
### 1. The `@contract` Decorator
Apply it directly above your class definition:
```python
from symai import Expression
from symai.strategy import contract
from symai.models import LLMDataModel
from typing import Optional, List # For type hints in examples
# Default retry parameters used if not overridden in the decorator call
DEFAULT_RETRY_PARAMS = {
"tries": 5, "delay": 0.5, "max_delay": 15,
"jitter": 0.1, "backoff": 2, "graceful": False
}
@contract(
pre_remedy: bool = False,
post_remedy: bool = True,
accumulate_errors: bool = False,
verbose: bool = False,
remedy_retry_params: dict = DEFAULT_RETRY_PARAMS # Uses defined defaults
)
class MyContractedClass(Expression):
# ... class implementation ...
pass
```
**Decorator Parameters and Defaults**:
* `pre_remedy` (bool, default: `False`): If `True`, attempts to automatically correct input validation failures (from your `pre` method) using LLM-based semantic remediation.
* `post_remedy` (bool, default: `True`): If `True`, attempts to automatically correct output validation failures (from your `post` method or type mismatches) using LLM-based type and semantic remediation.
* `accumulate_errors` (bool, default: `False`): Controls whether error messages from multiple failed validation attempts (during remediation) are accumulated and provided to the LLM in subsequent retry attempts. See more details in the "Error Accumulation" section below.
* `verbose` (bool, default: `False`): If `True`, enables detailed logging of the contract's internal operations, including prompts sent to the LLM and validation steps.
* `remedy_retry_params` (dict, default: `{ "tries": 5, "delay": 0.5, "max_delay": 15, "jitter": 0.1, "backoff": 2, "graceful": False }`): A dictionary configuring the retry behavior for both type and semantic validation/remediation functions.
* `tries` (int): Maximum number of retry attempts for a failed validation.
* `delay` (float): Initial delay (in seconds) before the first retry.
* `max_delay` (float): The maximum delay between retries.
* `jitter` (float): A factor for adding random jitter to delays to prevent thundering herd problems.
* `backoff` (float): The multiplier for increasing the delay between retries (e.g., 2 means delay doubles).
* `graceful` (bool): If `True`, suppresses exceptions during retry exhaustion and allows the contract to continue with potentially invalid state. In graceful mode:
* Exceptions from validation/remediation are suppressed and `self.contract_exception` remains `None`.
* The automatic final output type check (which would raise a `TypeError` for mismatched return types) is skipped, preventing upstream errors. This lets your `forward` method receive invalid or missing results without interruption and implement custom fallback logic.
* `dynamic_engine` (optional): A `symai.components.DynamicEngine` instance used for zero-shot fallback and remedy retries. When provided, retry/remedy calls run inside that engine context instead of the currently active default engine.
#### Optional: Run contract remedies on a dynamic engine
You can force retry/remedy attempts to execute on a different model by passing `dynamic_engine` inside `remedy_retry_params`.
```python
import os
from symai import Expression
from symai.components import DynamicEngine
from symai.strategy import contract
repair_engine = DynamicEngine(
model="claude-opus-4-6",
api_key=os.environ["ANTHROPIC_API_KEY"],
)
@contract(
pre_remedy=True,
post_remedy=True,
remedy_retry_params={
"tries": 3,
"delay": 0.4,
"max_delay": 4.0,
"jitter": 0.15,
"backoff": 1.8,
"graceful": False,
"dynamic_engine": repair_engine,
},
)
class MyContractedClass(Expression):
...
```
This keeps your main engine selection unchanged while routing contract correction passes through the specified dynamic engine.
### 2. Input and Output Data Models
**Note**: You can use native Python types directly in your `pre`, `act`, `post`, and `forward` method signatures (e.g., `str`, `int`, `list[int]`, `dict[str, int]`, `Optional[...]`, `Union[...]`), or mix them with traditional `LLMDataModel` types in hybrid scenarios (e.g., LLMDataModel inputs with list outputs). The system will dynamically generate internal LLMDataModel wrappers (with a single `value` field) for validation and automatically unwrap the `value` field back to your native data on return, making simple use cases more concise than defining full Pydantic models.
Your contract's core logic (especially `pre`, `act`, `post`, and `forward`) will operate on instances of `LLMDataModel`. Define these models using Pydantic syntax. Crucially, use `Field(description=\"...\")` for your model attributes, as these descriptions are used to generate more effective prompts for the LLM. Always use descriptive `Field(description=\"...\")` for your type data models, as these descriptions are crucial for guiding the LLM effectively during validation and generation steps. Rich descriptions help the `TypeValidationFunction` understand the semantic intent of each field, leading to better error messages and more accurate data generation when remedies are active.
```python
from pydantic import Field
class MyInput(LLMDataModel):
text: str = Field(description="The input text to be processed.")
max_length: Optional[int] = Field(default=None, description="Optional maximum length for processing.")
class MyIntermediate(LLMDataModel):
processed_text: str = Field(description="Text after initial processing by 'act'.")
entities_found: List[str] = Field(default_factory=list, description="Entities identified in 'act'.")
class MyOutput(LLMDataModel):
result: str = Field(description="The final processed result.")
is_valid: bool = Field(description="Indicates if the result is considered valid by post-conditions.")
```
### 3. The `prompt` Property
Your class must define a `prompt` property that returns a string. This prompt provides the high-level instructions or context to the LLM for the main task your class is designed to perform. It's particularly used by `TypeValidationFunction` (when semantic checks are guided by `pre`/`post` conditions and remedies are active) during the input (`pre_remedy`) and output (`post_remedy`) validation and remediation phases.
```python
@property
def prompt(self) -> str:
return "You are an expert assistant. Given the input text, process it and return a concise summary."
```
**Important Note on Prompts:** A contract's `prompt` should be considered fixed. Its role is to describe the fundamental task the contract must perform and should not mutate during the lifetime of the contract instance or based on specific inputs. If you have dynamic instructions or data that changes with each call, this should not be part of the `prompt` string itself. Instead, create a state object or pass such dynamic information as part of your input data model (e.g., a field named `dynamic_instruction` or similar). The `prompt` defines *what* the contract does in general, while the input provides the specific data for *that particular execution*.
### Error Accumulation (`accumulate_errors`)
The `accumulate_errors` parameter (default: `False`) in the `@contract` decorator influences how the underlying `TypeValidationFunction` (which handles both type and semantic validation, including remedies) handles repeated failures during the remedy process.
* **When `accumulate_errors = True`**: If a validation (e.g., a `post`-condition) fails, and a remedy attempt also fails, the error message from this failed remedy attempt is stored. If subsequent remedy attempts also fail, their error messages are appended to the list of previous errors. This accumulated list of errors is then provided as part of the context to the LLM in the next retry.
* **Benefits**: This can be very useful in complex scenarios. By seeing the history of what it tried and why those attempts were flagged as incorrect, the LLM might gain a better understanding of the constraints and be less likely to repeat the same mistakes. It's like showing the LLM its "thought process" and where it went wrong, potentially leading to more effective self-correction. This is particularly helpful if an initial fix inadvertently introduces a new problem that was previously not an issue, or if a previously fixed error reappears.
* **Potential Downsides**: In some cases, providing a long list of past errors (especially if they are somewhat contradictory or if the LLM fixed an issue that then reappears in the error list) could confuse the LLM. It might lead to an overly complex prompt that makes it harder for the model to focus on the most recent or critical issue.
* **When `accumulate_errors = False` (Default)**: Only the error message from the most recent failed validation/remedy attempt is provided to the LLM for the next retry. The history of previous errors is not explicitly passed.
* **Benefits**: This keeps the corrective prompt focused and simpler, potentially being more effective for straightforward errors where historical context isn't necessary or could be distracting.
* **Potential Downsides**: The LLM loses the context of previous failed attempts. It might retry solutions that were already found to be problematic or might reintroduce errors that it had previously fixed in an earlier iteration of the remedy loop for the same overall validation step.
Choosing whether to enable `accumulate_errors` depends on the complexity of your validation logic and how you observe the LLM behaving during remediation. If you find the LLM cycling through similar errors or reintroducing past mistakes, setting `accumulate_errors=True` might be beneficial. If the remediation prompts become too noisy or confusing, `False` might be preferable.
### 4. The `pre(self, input: MyInput) -> bool` Method
This method defines the pre-conditions for your contract. It's called with the validated input object (`current_input` in `strategy.py`, which has already passed the `_is_valid_input` type check).
* **Signature**: `def pre(self, input: YourInputModel) -> bool:`
* **Behavior**:
* If all pre-conditions are met, it should do nothing or simply `return True`. (Note: The `bool` return type is conventional; the primary success signal is the absence of an exception).
* If a pre-condition is violated, it **must raise an exception**. The exception's message should be descriptive, as it will be used to guide the LLM if `pre_remedy` is enabled.
```python
def pre(self, input: MyInput) -> bool:
if not input.text:
raise ValueError("Input text cannot be empty. Please provide some text to process.")
if input.max_length is not None and len(input.text) > input.max_length:
raise ValueError(f"Input text exceeds maximum length of {input.max_length}. Please provide shorter text.")
return True
```
### 5. The `act(self, input: MyInput, **kwargs) -> MyIntermediate` Method (Optional)
The `act` method provides an optional intermediate processing step that occurs *after* input pre-validation (and potential pre-remedy) and *before* the main output validation/generation phase (`_validate_output`).
* **Signature**: `def act(self, act_input: YourInputModelOrActInputModel, **kwargs) -> YourIntermediateModel:`
* The decorator treats the **first positional or positional-or-keyword parameter after `self`** as the contract input. You can keep naming it `input` for clarity, but any valid identifier works.
* That parameter must be type-hinted with an `LLMDataModel` subclass (or a Python type that can be wrapped dynamically). The method must also declare a return type annotation so the contract knows which `LLMDataModel` to build next.
* `**kwargs` from the original call—excluding the canonical input argument—are passed through to `act`.
* **Behavior**:
* Perform transformations on the `input`, computations, or state updates on `self`.
* The object returned by `act` becomes the `current_input` for the `_validate_output` stage (where the LLM is typically called to generate the final output type).
* Can modify `self` (e.g., update instance counters, accumulate history).
```python
# Example: Add a counter to the class for state mutation
# def __init__(self, *args, **kwargs):
# super().__init__(*args, **kwargs)
# self.calls_count = 0
def act(self, input: MyInput, **kwargs) -> MyIntermediate:
# self.calls_count += 1 # Example of state mutation
processed_text = input.text.strip().lower()
# Example: simple entity "extraction"
entities = [word for word in processed_text.split() if len(word) > 5]
return MyIntermediate(processed_text=processed_text, entities_found=entities)
```
### 6. The `post(self, output: MyOutput) -> bool` Method
This method defines the post-conditions. It's called by `_validate_output` with an instance of the `forward` method's declared return type (e.g., `MyOutput`). This instance is typically generated by an LLM call within `_validate_output` based on your class's `prompt` and the (potentially `act`-modified) input.
* **Signature**: `def post(self, output: YourOutputModel) -> bool:`
* **Behavior**:
* If all post-conditions are met, `return True`.
* If a post-condition is violated, **raise an exception** with a descriptive message. This message guides LLM self-correction if `post_remedy` is enabled.
```python
def post(self, output: MyOutput) -> bool:
if not output.result:
raise ValueError("The final result string cannot be empty.")
if output.is_valid is False and len(output.result) < 10:
raise ValueError("If result is marked invalid, it should at least have a short explanation (min 10 chars).")
# Example: could use self.custom_threshold modified by act
# if hasattr(self, 'custom_threshold') and output.some_score < self.custom_threshold:
# raise ValueError("Score too low based on dynamic threshold.")
return True
```
### 7. The `forward(self, input: MyInput, **kwargs) -> MyOutput` Method
This is your class's original `forward` method, containing the primary logic. The `@contract` decorator wraps this method.
* **Signature**: `def forward(self, model_input: YourInputModel, **kwargs) -> YourOutputModel:`
* The decorator binds the **first positional or positional-or-keyword parameter after `self`** as the canonical contract input. Naming the parameter `input` is still idiomatic, but any identifier works.
* That parameter must be type-hinted with an `LLMDataModel` subclass (or a Python type that the decorator can wrap dynamically) compatible with your `pre`/`act` expectations.
* The method **must have a return type annotation** (e.g., `-> YourOutputModel`), which must be an `LLMDataModel` subclass. This declared type is crucial for the contract's type validation and output generation phases.
* Calls may use positional or keyword arguments interchangeably; any remaining `**kwargs` are forwarded unchanged to your logic and downstream engines.
* **Behavior**:
* This method is **always called** by the contract's `wrapped_forward` (in its `finally` block), regardless of whether the preceding contract validations (`pre`, `act`, `post`, remedies) succeeded or failed.
* **Developer Responsibility**: Inside your `forward` method, you *must* check `self.contract_successful` and/or `self.contract_result`.
* If `self.contract_successful` is `True`, `self.contract_result` holds the validated (and possibly remedied) output from the contract pipeline. You should typically return this.
* If `self.contract_successful` is `False`, the contract failed. `self.contract_result` might be `None` or an intermediate (invalid) object, and `self.contract_exception` holds the underlying exception from the contract pipeline. In this case, your `forward` method can:
* Return a sensible default object that matches `YourOutputModel`.
* Or, if you prefer to propagate the error, raise it to preserve the original context, e.g.,
```python
raise self.contract_exception or ValueError("Contract failed!")
```
* The argument bound to your first non-`self` parameter (e.g., `model_input`) depends on whether the contract succeeded:
* If `contract_successful == True`: that argument is the `current_input` from `wrapped_forward` which was used by `_validate_output`. This `current_input` is the output of `_act` if `act` is defined, otherwise it's the output of `_validate_input`.
* If `contract_successful == False`: that argument is the `original_input` (the raw value provided to the contract call, after initial type validation by `_is_valid_input` but before `pre` or `act` modifications).
```python
def forward(self, input: MyInput, **kwargs) -> MyOutput:
if not self.contract_successful or self.contract_result is None:
# Contract failed, or result is not set: implement fallback
return MyOutput(result="Error: Processing failed due to contract violation.", is_valid=False)
# Contract succeeded, self.contract_result holds the validated output
# You can do further processing on self.contract_result if needed,
# or simply return it.
final_result: MyOutput = self.contract_result
final_result.result += " (Forward processed)" # Example of further work
return final_result
```
#### Input Binding Rules
The contract wrapper now resolves the canonical input value without requiring an `input=` keyword argument. The resolution order is:
1. The first positional argument supplied when you call the contracted instance (i.e., `my_expr(my_input)`).
2. If no positional value is provided, the first positional-or-keyword parameter defined after `self` in your `forward` signature (for example, `model_input`) is fetched from `**kwargs`.
3. As a backwards-compatible fallback, an explicit `input=` keyword argument is still accepted.
The resolved object is then passed consistently through `_is_valid_input`, `pre`, `act`, `_validate_output`, and finally your original `forward` method. All remaining keyword arguments are forwarded untouched.
#### Error Handling and Propagation
When a contract validation or remediation step fails, the exception is captured in `self.contract_exception`, and `self.contract_successful` is set to `False`. If you prefer to surface these errors instead of returning fallback values, you can propagate the exception in your `forward` implementation:
```python
def forward(self, input: MyInput, **kwargs) -> MyOutput:
if self.contract_result is None:
# Propagate the original contract exception, or a generic one
raise self.contract_exception or ValueError("Contract failed!")
return self.contract_result
```
```python
# Example: graceful=True → suppressed errors, skip type check (can return any type)
# Contract decorator configured as:
# @contract(pre_remedy=False, post_remedy=True, remedy_retry_params={"graceful": True, ...})
class MyExpr(Expression):
def forward(self, input: MyInput, **kwargs) -> MyOutput:
# In graceful mode, contract_exception is None on failures,
# and the final output type check is skipped.
# You may return a completely different type than the annotation.
if not self.contract_successful or self.contract_result is None:
# Fallback logic returning a raw dict instead of MyOutput
return {
"status": "error",
"message": "Fallback allowed under graceful mode"
}
# On success, return the validated contract result
return self.contract_result
```
### Ensuring Meaningful Output: The Importance of `pre` and `post` Conditions
It's quite easy to end up with a meaningless, "gibberish" object if you never really validate its contents. The role of `pre` and `post` conditions is exactly that: to ensure not just the shape but also the substance of your data.
Before, the system might have returned a dummy filler object by default, even before the prompt was passed into the type-validation function. Now, while the prompt is wired through that function and the object should populate more sensibly, a core principle remains:
> If the `post` method doesn't fail – either because no `ValueError` was thrown or because you skipped all semantic checks (e.g., by simply having `post` return `True`) – the contract will happily hand you back whatever came out of the type-validation step.
Since the `TypeValidationFunction` (which handles the type-validation step) primarily enforces "is this a valid instance of the target type?" and doesn't inherently care what the fields contain beyond basic type conformance, you might get dummy values or inadequately populated fields unless you specify richer constraints.
So, if your `LLMDataModel` types lack meaningful `Field(description="...")` attributes and your `prompt` isn't explicit enough, you might just get randomness or minimally populated objects. This is expected behavior. The contract pattern isn't broken; it's doing exactly what you told it to: validate shape, and substance *only if you explicitly define checks for it*.
To illustrate, say you want a non-trivial `title: str` in your output object, but you never write a `post` check to validate its content (e.g., `if not output.title or len(output.title) < 10: raise ValueError("Title is missing or too short")`). In such a case, you might keep receiving a placeholder string or an inadequately generated title. While passing the main prompt into the `TypeValidationFunction` helps it try to generate something relevant, without a `post`-condition to enforce your specific requirements, you might still see undesirable behavior.
**In short: the contract pattern is doing its job. If you want substance, you must codify those semantic rules in your `LLMDataModel` field descriptions and, critically, in your `pre` and `post` validation checks.**
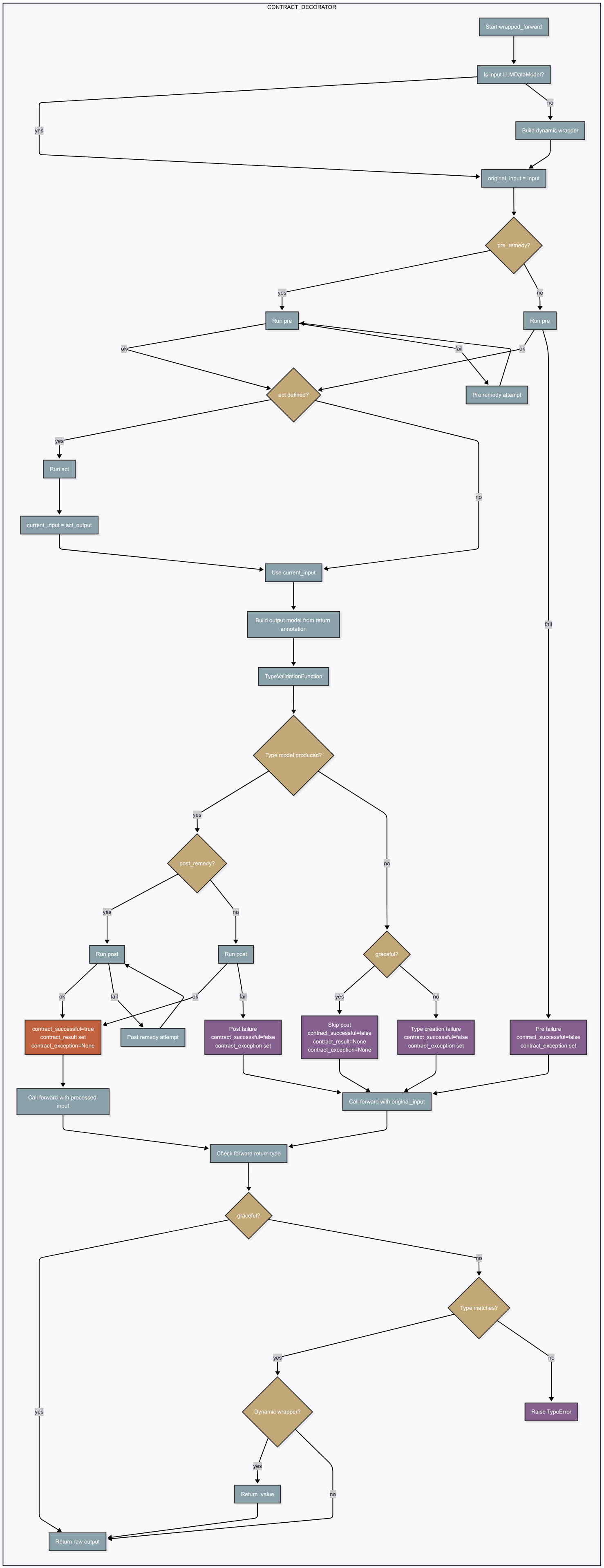
## Contract Execution Flow
When you call an instance of your contracted class (e.g., `my_instance(my_input_data)` or `my_instance(input=my_input_data)`), the `wrapped_forward` method (created by the `@contract` decorator) executes the following sequence:
1. **Return Type Annotation Validation & Dynamic Wrapping (`_is_valid_output` + `_try_dynamic_type_annotation`)**:
* Inspects your `forward` method's return type annotation (`sig.return_annotation`).
* Ensures you provided a return type annotation and it’s a subclass of `LLMDataModel`.
* If the annotation is a native Python/typing type (e.g., `str`, `list[int]`, `Optional[...]`), the system automatically builds a dynamic `LLMDataModel` wrapper for the output type, allowing subsequent validation and unwrapping.
2. **Initial Input Collection & Dynamic Wrapping (`_is_valid_input` + `_try_dynamic_type_annotation`)**:
* Determines the canonical contract input by prioritizing the first positional argument after `self`. If no positional value is provided, it falls back to the first compatible keyword (preferring the corresponding parameter name, then `input` for backward compatibility).
* Validates that canonical value with `_is_valid_input` and stores it as `original_input`.
* If the value is a native Python type (and not already an `LLMDataModel`), the system inspects your `forward` signature to infer the expected Python type and automatically wraps your primitive or container in a temporary `LLMDataModel` for validation (via `_try_dynamic_type_annotation`).
3. **Pre-condition Validation (`_validate_input`)**:
* The `current_input` (initially `original_input`) is passed to your `pre(input)` method.
* If `pre()` raises an exception and `pre_remedy=True`, `SemanticValidationFunction` attempts to correct the `current_input` based on the exception message from `pre()` and your class's `prompt`.
* If `pre()` raises and `pre_remedy=False` (or remedy fails), an `Exception("Pre-condition validation failed!")` is raised (this exception is then handled by `wrapped_forward`'s main `try...except` block).
4. **Intermediate Action (`_act`)**:
* If your class defines an `act` method:
* Its signature is validated to ensure the first positional (or positional-or-keyword) parameter after `self` is type-hinted, and the return annotation is present.
* `act(current_input, **act_kwargs)` is called. `current_input` here is the output from the pre-condition validation step.
* The result of `act` becomes the new `current_input`.
* The actual type of `act`'s return value is checked against its annotation.
* If no `act` method, `current_input` remains unchanged.
5. **Output Validation & Generation (`_validate_output`)**:
* This is a critical step, especially when `post_remedy=True`.
* It uses `TypeValidationFunction` and (if `post_remedy=True`) `SemanticValidationFunction`.
* The goal is to produce an object that matches your `forward` method's return type annotation (e.g., `MyOutput`).
* The `current_input` (which is the output from `_act`, or from `_validate_input` if no `act`) and your class's `prompt` are used to guide an LLM call to generate/validate data conforming to the target output type.
* Your `post(output)` method is called with the LLM-generated/validated output object.
* If `post()` raises an exception and `post_remedy=True`, remediation is attempted.
* If your `forward` return annotation is a native Python type or typing construct (e.g., `int`, `list[str]`, `dict[str, int]`, `Optional[...]`, `Union[...]`), the contract will build a dynamic `LLMDataModel` wrapper for the output, validate and (if needed) remediate it, then automatically unwrap and return the native value on exit.
* If all these steps (type validation, LLM generation, `post` validation, remedies) succeed:
* `self.contract_successful` is set to `True`.
* `self.contract_result` is set to the final, validated output object.
* This output is typically assigned to `final_output` within the `try` block of `wrapped_forward` (the method created by the decorator).
6. **Exception Handling in Main Path (`wrapped_forward`'s `try...except`)**:
* Steps 2, 3, and 4 (pre-validation, act, and output validation/generation) are wrapped in a `try...except Exception as e:` block within the decorator's logic.
* If any exception occurs during these steps (e.g., an unrecoverable failure in `_validate_input`, `_act`, or `_validate_output`), the `logger` records it, and `self.contract_successful` is set to `False`.
7. **Final Execution (`finally` block of `wrapped_forward`)**:
* This block **always executes**, regardless of success or failure in the preceding `try` block.
* It determines the `forward_input` for your original `forward` method:
* If `self.contract_successful` is `True`, `forward_input` is the `current_input` that successfully passed through `_act` and was used by `_validate_output`.
* If `self.contract_successful` is `False`, `forward_input` is the `original_input`.
* Your class's original `forward` method is invoked with that canonical input reinserted (as the first positional argument or matching keyword) alongside the untouched auxiliary `**kwargs`.
* The value returned by *your* `forward` method becomes the ultimate return value of the contract call.
* A final output type check is performed on this returned value against your `forward` method's declared return type annotation. If the contract is configured with `graceful=True`, this final type check is skipped instead of raising a `TypeError`.
## Example
This is a 0-shot example generated by o3 from the above documentation and tests.
```python
# ──────────────────────────────────────────────────────────────
# Standard library │
# ──────────────────────────────────────────────────────────────
from typing import List, Optional
from pydantic import Field
# ──────────────────────────────────────────────────────────────
# SymbolicAI core │
# ──────────────────────────────────────────────────────────────
from symai import Expression # Base class for your LLM “operators”
from symai.models import LLMDataModel # Thin Pydantic wrapper w/ LLM hints
from symai.strategy import contract # The Design-by-Contract decorator
# ▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
# 1. Data models ▬
# – clear structure + rich Field descriptions power ▬
# validation, automatic prompt templating & remedies ▬
# ▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
class Document(LLMDataModel):
"""Represents an entire document in the tiny in-memory corpus."""
id: str = Field(description="Unique identifier of the document.")
content: str = Field(description="The full raw text of the document.")
class DocSnippet(LLMDataModel):
"""
Exact passage taken *verbatim* from a Document.
We store the `doc_id` so the answer can cite its source.
"""
doc_id: str = Field(description="ID of the document the snippet comes from.")
snippet: str = Field(description="A short excerpt supporting the answer.")
class MultiDocQAInput(LLMDataModel):
"""
The *input* to the contract call:
• the user’s natural-language question
• the corpus it may answer from
• a caller-specified upper bound on how many snippets can be cited
"""
query: str = Field(description="User question in plain English.")
documents: List[Document] = Field(description="Corpus to search for answers.")
max_snippets: Optional[int] = Field(
default=3,
ge=1,
le=10,
description="Max number of snippets the agent may cite (defaults to 3).",
)
class IntermediateRetrieved(LLMDataModel):
"""
Returned by `act()`: lightweight retrieval result that will be fed to
the LLM so it can see relevant sentences without scanning whole docs.
"""
query: str = Field(description="The original question from the user.")
top_docs: List[Document] = Field(description="Top-k most relevant documents.")
selected_sentences: List[str] = Field(
description="Sentences deemed most relevant to the query."
)
target_snippet_count: int = Field(
description="Upper bound on evidence snippets (copied from input)."
)
class AnswerWithEvidence(LLMDataModel):
"""
Final object returned to the **caller** (and validated by `post`).
"""
answer: str = Field(description="Concise, stand-alone answer.")
evidence: List[DocSnippet] = Field(description="Cited supporting passages.")
coverage_score: float = Field(
ge=0.0,
le=1.0,
description=(
"LLM-estimated fraction of answer that is directly supported by the "
"evidence (0 = no support, 1 = fully supported)."
),
)
# ▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
# 2. The contracted class ▬
# ▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
@contract(
# ── Remedies ─────────────────────────────────────────── #
pre_remedy=True, # Try to fix bad inputs automatically
post_remedy=True, # Try to fix bad LLM outputs automatically
accumulate_errors=True, # Feed history of errors to each retry
verbose=True, # Log internal steps (see `symai.strategy` logger)
remedy_retry_params=dict(tries=3, delay=0.4, max_delay=4.0,
jitter=0.15, backoff=1.8, graceful=False),
)
class MultiDocQAgent(Expression):
"""
High-level behaviour:
1. `pre` – sanity-check query & docs
2. `act` – *retrieve* relevant sentences, mutate state
3. LLM – generate AnswerWithEvidence (handled by SymbolicAI engine)
4. `post` – ensure answer & evidence meet semantic rules
5. `forward`
• if contract succeeded → return type validated LLM object
• else → graceful fallback answer
"""
# ───────────────────────── init ───────────────────────── #
def __init__(self, min_coverage: float = 0.55, *args, **kwargs):
super().__init__(*args, **kwargs)
self.min_coverage = min_coverage # threshold for `post`
self.interaction_log: list[dict] = [] # keeps a history of queries
# ───────────────────────── prompt ─────────────────────── #
@property
def prompt(self) -> str:
"""
A *static* description of what the LLM must do.
Braces {{like_this}} will be replaced with fields from
the object produced by `_validate_input`/`_act`.
"""
return (
"You are an expert research assistant.\n"
"Given a QUESTION and a set of RELEVANT_SENTENCES, write a concise "
"answer. Cite every passage you use exactly as `(Doc )`. "
"Respond with a JSON object that fits the AnswerWithEvidence schema."
)
# ───────────────────────── pre ────────────────────────── #
def pre(self, input: MultiDocQAInput) -> bool:
"""
Guard-clauses before we even *touch* the LLM.
Raise ValueError with human-readable messages – they become corrective
prompts if `pre_remedy=True`.
"""
if not input.query.strip():
raise ValueError("The query must not be empty.")
if not input.documents:
raise ValueError("You must supply at least one document.")
return True # all good
# ───────────────────────── act ────────────────────────── #
def act(self, input: MultiDocQAInput, **kwargs) -> IntermediateRetrieved:
"""
Lightweight pseudo-retrieval.
Steps:
• score each doc by term overlap with the query
• keep top-k (k ≤ 3)
• within each, take two most overlapping sentences
• log the interaction for later analytics
"""
k = min(3, len(input.documents))
query_terms = {t.lower() for t in input.query.split()}
# Score documents by *crude* term overlap
scored_docs = []
for doc in input.documents:
overlap = sum(t in query_terms for t in doc.content.lower().split())
scored_docs.append((overlap, doc))
scored_docs.sort(reverse=True, key=lambda x: x[0])
top_docs = [doc for _, doc in scored_docs[:k]]
# Extract at most 2 high-overlap sentences from each top doc
selected_sentences: list[str] = []
for doc in top_docs:
sentences = [s.strip() for s in doc.content.split(".") if s.strip()]
sentences.sort(
reverse=True,
key=lambda s: sum(t in query_terms for t in s.lower().split()),
)
selected_sentences.extend(sentences[:2])
# Record what we did (just for analytics / debugging)
self.interaction_log.append(
{
"query": input.query,
"num_docs": len(input.documents),
"top_doc_ids": [d.id for d in top_docs],
}
)
# Return a *different* LLMDataModel; this becomes the
# `current_input` for the output-validation phase.
return IntermediateRetrieved(
query=input.query,
top_docs=top_docs,
selected_sentences=selected_sentences,
target_snippet_count=input.max_snippets or 3,
)
# ───────────────────────── post ───────────────────────── #
def post(self, output: AnswerWithEvidence) -> bool:
"""
Semantic guarantees:
• non-empty answer
• coverage ≥ threshold
• high-coverage → must actually cite evidence
• evidence list ≤ `target_snippet_count` learned in `act`
Any violation ⇒ raise ValueError (triggers post-remedy or failure).
"""
if not output.answer.strip():
raise ValueError("Answer text is empty.")
# coverage gate
if output.coverage_score < self.min_coverage:
raise ValueError(
f"Coverage score {output.coverage_score:.2f} "
f"is below the minimum {self.min_coverage:.2f}."
)
# If it claims high coverage but provides no evidence, that's fishy
if output.coverage_score >= 0.8 and not output.evidence:
raise ValueError(
"High coverage claims require at least one evidence snippet."
)
# Enforce caller’s snippet bound (act stored it on self._current_input)
max_allowed = getattr(self, "_current_input", None)
if (
isinstance(max_allowed, IntermediateRetrieved)
and output.evidence
and len(output.evidence) > max_allowed.target_snippet_count
):
raise ValueError(
f"Too many snippets ({len(output.evidence)}), "
f"maximum allowed is {max_allowed.target_snippet_count}."
)
return True # all checks passed
# ───────────────────────── forward ────────────────────── #
def forward(self, input: MultiDocQAInput, **kwargs) -> AnswerWithEvidence:
"""
ALWAYS executed (even if contract failed).
Success path → return the LLM-validated object (`self.contract_result`)
Failure path → build a polite fallback answer that still matches schema
"""
# ── happy path ─────────────────────────────────────── #
if self.contract_successful and self.contract_result:
return self.contract_result
# ── fallback (contract failed) ─────────────────────── #
first_doc = input.documents[0]
first_sentence = first_doc.content.split(".")[0][:300] # keep it short
return AnswerWithEvidence(
answer=(
"I’m not confident enough to answer precisely. "
"Please re-phrase the question or provide more documents."
),
evidence=[DocSnippet(doc_id=first_doc.id, snippet=first_sentence)],
coverage_score=0.0,
)
if __name__ == "__main__":
# ▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
# 3. Mini-demo (only executed when you run the file directly) ▬
# ▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
# ── tiny “corpus” ─────────────────────────────────────── #
docs = [
Document(
id="A1",
content=(
"Symbolic AI combines formal logic with modern machine learning. "
"It allows transparent reasoning and explicit knowledge "
"representation while still benefiting from statistical models."
),
),
Document(
id="B2",
content=(
"Vector databases store embeddings of documents. They let users "
"quickly retrieve text that is semantically similar to a query "
"vector, enabling high-quality semantic search."
),
),
Document(
id="C3",
content=(
"Hybrid search merges sparse keyword techniques and dense vector "
"similarity, improving recall and precision, especially for "
"domain-specific collections."
),
),
]
# ── create agent instance ─────────────────────────────── #
agent = MultiDocQAgent(min_coverage=0.6)
# ── ask a question ────────────────────────────────────── #
question = "Why are vector databases useful for semantic search?"
result = agent(
input=MultiDocQAInput(
query=question,
documents=docs,
max_snippets=2, # caller sets stricter evidence limit
)
)
# ── result ───────────────────────––––––––––––––––––––––– #
print("\nAnswer:\n", result.answer)
print("\nCoverage:", result.coverage_score)
print("\nEvidence:")
for ev in result.evidence:
print(f" • (Doc {ev.doc_id}) {ev.snippet}")
agent.contract_perf_stats();
```
## Why Use Contracts?
Traditional software development often relies on testing to verify correctness after the fact. Contracts, however, encourage building correctness into the design itself. When working with LLMs, which are inherently probabilistic, ensuring that outputs are not only syntactically valid but also semantically meaningful and contextually appropriate is crucial.
Contracts in SymbolicAI help bridge this gap by:
1. **Enforcing Semantic Guarantees**: Beyond static type checking (which ensures structural validity), contracts allow you to define and validate what your `Expression`'s inputs and outputs *mean* in a given context.
2. **Guiding LLM Behavior**: The error messages raised by failed pre-conditions and post-conditions are used as corrective prompts, enabling the LLM to attempt self-correction. This turns validation failures into learning opportunities for the model.
3. **Proactive Structuring**: Designing a contract forces careful consideration of inputs, outputs, and invariants, shifting from reactive validation to proactive structuring of your logic.
4. **Improving Predictability and Reliability**: By setting clear expectations and validation steps, contracts make your AI components more predictable and less prone to unexpected or undesirable outputs (like hallucinations).
5. **Enhancing Composability**: Clear contracts at the interface level allow different components (potentially powered by different LLMs or even rule-based systems) to interoperate reliably, as long as they satisfy the agreed-upon contractual obligations.
## What is a `@contract` in SymbolicAI?
The `@contract` is a class decorator that you apply to your custom classes inheriting from `symai.Expression`. It augments your class, particularly its `forward` method, by wrapping it with a validation and execution pipeline.
Key characteristics:
* **Operates on LLMDataModel or Python types**: Inputs to and outputs from the core contract-validated logic can be instances of `symai.models.LLMDataModel` (extending Pydantic's `BaseModel`) or native Python types (e.g., `str`, `int`, `list[int]`, `dict[str, int]`, `Optional[...]`, `Union[...]`). Dynamic type annotation automatically wraps primitive or complex Python types into internal LLMDataModel wrappers (with a single `value` field) for validation and unwrapping, reducing verbosity compared to defining full LLMDataModel classes for simple use cases.
* **User-Defined Conditions**: You define the contract's terms by implementing specific methods: `pre` (pre-conditions), `act` (optional intermediate action), and `post` (post-conditions), along with a `prompt` property.
* **Fallback Mechanism**: A contract never entirely prevents the execution of your class's original `forward` method. If contract validation fails (even after remedies), your `forward` method is still called (typically with the original, unvalidated input, if the failure happened before `act`, or the `act`-modified input if failure was in `post`), allowing you to implement fallback logic or return a default, type-compliant object.
* **State and Results**: The decorator adds attributes to your class instance:
* `self.contract_successful` (bool): Indicates if all contract validations (including remedies) passed.
* `self.contract_result` (Any): Holds the validated and potentially remedied output if successful; otherwise, it might be `None` or an intermediate value if an error occurred before `_validate_output` completed successfully.
* `self.contract_perf_stats()` (method): Returns a dictionary with performance metrics for various stages of the contract execution.
## Core Components of a Contracted Class
To use the `@contract` decorator, you'll define several key components within your `Expression` subclass:
### 1. The `@contract` Decorator
Apply it directly above your class definition:
```python
from symai import Expression
from symai.strategy import contract
from symai.models import LLMDataModel
from typing import Optional, List # For type hints in examples
# Default retry parameters used if not overridden in the decorator call
DEFAULT_RETRY_PARAMS = {
"tries": 5, "delay": 0.5, "max_delay": 15,
"jitter": 0.1, "backoff": 2, "graceful": False
}
@contract(
pre_remedy: bool = False,
post_remedy: bool = True,
accumulate_errors: bool = False,
verbose: bool = False,
remedy_retry_params: dict = DEFAULT_RETRY_PARAMS # Uses defined defaults
)
class MyContractedClass(Expression):
# ... class implementation ...
pass
```
**Decorator Parameters and Defaults**:
* `pre_remedy` (bool, default: `False`): If `True`, attempts to automatically correct input validation failures (from your `pre` method) using LLM-based semantic remediation.
* `post_remedy` (bool, default: `True`): If `True`, attempts to automatically correct output validation failures (from your `post` method or type mismatches) using LLM-based type and semantic remediation.
* `accumulate_errors` (bool, default: `False`): Controls whether error messages from multiple failed validation attempts (during remediation) are accumulated and provided to the LLM in subsequent retry attempts. See more details in the "Error Accumulation" section below.
* `verbose` (bool, default: `False`): If `True`, enables detailed logging of the contract's internal operations, including prompts sent to the LLM and validation steps.
* `remedy_retry_params` (dict, default: `{ "tries": 5, "delay": 0.5, "max_delay": 15, "jitter": 0.1, "backoff": 2, "graceful": False }`): A dictionary configuring the retry behavior for both type and semantic validation/remediation functions.
* `tries` (int): Maximum number of retry attempts for a failed validation.
* `delay` (float): Initial delay (in seconds) before the first retry.
* `max_delay` (float): The maximum delay between retries.
* `jitter` (float): A factor for adding random jitter to delays to prevent thundering herd problems.
* `backoff` (float): The multiplier for increasing the delay between retries (e.g., 2 means delay doubles).
* `graceful` (bool): If `True`, suppresses exceptions during retry exhaustion and allows the contract to continue with potentially invalid state. In graceful mode:
* Exceptions from validation/remediation are suppressed and `self.contract_exception` remains `None`.
* The automatic final output type check (which would raise a `TypeError` for mismatched return types) is skipped, preventing upstream errors. This lets your `forward` method receive invalid or missing results without interruption and implement custom fallback logic.
* `dynamic_engine` (optional): A `symai.components.DynamicEngine` instance used for zero-shot fallback and remedy retries. When provided, retry/remedy calls run inside that engine context instead of the currently active default engine.
#### Optional: Run contract remedies on a dynamic engine
You can force retry/remedy attempts to execute on a different model by passing `dynamic_engine` inside `remedy_retry_params`.
```python
import os
from symai import Expression
from symai.components import DynamicEngine
from symai.strategy import contract
repair_engine = DynamicEngine(
model="claude-opus-4-6",
api_key=os.environ["ANTHROPIC_API_KEY"],
)
@contract(
pre_remedy=True,
post_remedy=True,
remedy_retry_params={
"tries": 3,
"delay": 0.4,
"max_delay": 4.0,
"jitter": 0.15,
"backoff": 1.8,
"graceful": False,
"dynamic_engine": repair_engine,
},
)
class MyContractedClass(Expression):
...
```
This keeps your main engine selection unchanged while routing contract correction passes through the specified dynamic engine.
### 2. Input and Output Data Models
**Note**: You can use native Python types directly in your `pre`, `act`, `post`, and `forward` method signatures (e.g., `str`, `int`, `list[int]`, `dict[str, int]`, `Optional[...]`, `Union[...]`), or mix them with traditional `LLMDataModel` types in hybrid scenarios (e.g., LLMDataModel inputs with list outputs). The system will dynamically generate internal LLMDataModel wrappers (with a single `value` field) for validation and automatically unwrap the `value` field back to your native data on return, making simple use cases more concise than defining full Pydantic models.
Your contract's core logic (especially `pre`, `act`, `post`, and `forward`) will operate on instances of `LLMDataModel`. Define these models using Pydantic syntax. Crucially, use `Field(description=\"...\")` for your model attributes, as these descriptions are used to generate more effective prompts for the LLM. Always use descriptive `Field(description=\"...\")` for your type data models, as these descriptions are crucial for guiding the LLM effectively during validation and generation steps. Rich descriptions help the `TypeValidationFunction` understand the semantic intent of each field, leading to better error messages and more accurate data generation when remedies are active.
```python
from pydantic import Field
class MyInput(LLMDataModel):
text: str = Field(description="The input text to be processed.")
max_length: Optional[int] = Field(default=None, description="Optional maximum length for processing.")
class MyIntermediate(LLMDataModel):
processed_text: str = Field(description="Text after initial processing by 'act'.")
entities_found: List[str] = Field(default_factory=list, description="Entities identified in 'act'.")
class MyOutput(LLMDataModel):
result: str = Field(description="The final processed result.")
is_valid: bool = Field(description="Indicates if the result is considered valid by post-conditions.")
```
### 3. The `prompt` Property
Your class must define a `prompt` property that returns a string. This prompt provides the high-level instructions or context to the LLM for the main task your class is designed to perform. It's particularly used by `TypeValidationFunction` (when semantic checks are guided by `pre`/`post` conditions and remedies are active) during the input (`pre_remedy`) and output (`post_remedy`) validation and remediation phases.
```python
@property
def prompt(self) -> str:
return "You are an expert assistant. Given the input text, process it and return a concise summary."
```
**Important Note on Prompts:** A contract's `prompt` should be considered fixed. Its role is to describe the fundamental task the contract must perform and should not mutate during the lifetime of the contract instance or based on specific inputs. If you have dynamic instructions or data that changes with each call, this should not be part of the `prompt` string itself. Instead, create a state object or pass such dynamic information as part of your input data model (e.g., a field named `dynamic_instruction` or similar). The `prompt` defines *what* the contract does in general, while the input provides the specific data for *that particular execution*.
### Error Accumulation (`accumulate_errors`)
The `accumulate_errors` parameter (default: `False`) in the `@contract` decorator influences how the underlying `TypeValidationFunction` (which handles both type and semantic validation, including remedies) handles repeated failures during the remedy process.
* **When `accumulate_errors = True`**: If a validation (e.g., a `post`-condition) fails, and a remedy attempt also fails, the error message from this failed remedy attempt is stored. If subsequent remedy attempts also fail, their error messages are appended to the list of previous errors. This accumulated list of errors is then provided as part of the context to the LLM in the next retry.
* **Benefits**: This can be very useful in complex scenarios. By seeing the history of what it tried and why those attempts were flagged as incorrect, the LLM might gain a better understanding of the constraints and be less likely to repeat the same mistakes. It's like showing the LLM its "thought process" and where it went wrong, potentially leading to more effective self-correction. This is particularly helpful if an initial fix inadvertently introduces a new problem that was previously not an issue, or if a previously fixed error reappears.
* **Potential Downsides**: In some cases, providing a long list of past errors (especially if they are somewhat contradictory or if the LLM fixed an issue that then reappears in the error list) could confuse the LLM. It might lead to an overly complex prompt that makes it harder for the model to focus on the most recent or critical issue.
* **When `accumulate_errors = False` (Default)**: Only the error message from the most recent failed validation/remedy attempt is provided to the LLM for the next retry. The history of previous errors is not explicitly passed.
* **Benefits**: This keeps the corrective prompt focused and simpler, potentially being more effective for straightforward errors where historical context isn't necessary or could be distracting.
* **Potential Downsides**: The LLM loses the context of previous failed attempts. It might retry solutions that were already found to be problematic or might reintroduce errors that it had previously fixed in an earlier iteration of the remedy loop for the same overall validation step.
Choosing whether to enable `accumulate_errors` depends on the complexity of your validation logic and how you observe the LLM behaving during remediation. If you find the LLM cycling through similar errors or reintroducing past mistakes, setting `accumulate_errors=True` might be beneficial. If the remediation prompts become too noisy or confusing, `False` might be preferable.
### 4. The `pre(self, input: MyInput) -> bool` Method
This method defines the pre-conditions for your contract. It's called with the validated input object (`current_input` in `strategy.py`, which has already passed the `_is_valid_input` type check).
* **Signature**: `def pre(self, input: YourInputModel) -> bool:`
* **Behavior**:
* If all pre-conditions are met, it should do nothing or simply `return True`. (Note: The `bool` return type is conventional; the primary success signal is the absence of an exception).
* If a pre-condition is violated, it **must raise an exception**. The exception's message should be descriptive, as it will be used to guide the LLM if `pre_remedy` is enabled.
```python
def pre(self, input: MyInput) -> bool:
if not input.text:
raise ValueError("Input text cannot be empty. Please provide some text to process.")
if input.max_length is not None and len(input.text) > input.max_length:
raise ValueError(f"Input text exceeds maximum length of {input.max_length}. Please provide shorter text.")
return True
```
### 5. The `act(self, input: MyInput, **kwargs) -> MyIntermediate` Method (Optional)
The `act` method provides an optional intermediate processing step that occurs *after* input pre-validation (and potential pre-remedy) and *before* the main output validation/generation phase (`_validate_output`).
* **Signature**: `def act(self, act_input: YourInputModelOrActInputModel, **kwargs) -> YourIntermediateModel:`
* The decorator treats the **first positional or positional-or-keyword parameter after `self`** as the contract input. You can keep naming it `input` for clarity, but any valid identifier works.
* That parameter must be type-hinted with an `LLMDataModel` subclass (or a Python type that can be wrapped dynamically). The method must also declare a return type annotation so the contract knows which `LLMDataModel` to build next.
* `**kwargs` from the original call—excluding the canonical input argument—are passed through to `act`.
* **Behavior**:
* Perform transformations on the `input`, computations, or state updates on `self`.
* The object returned by `act` becomes the `current_input` for the `_validate_output` stage (where the LLM is typically called to generate the final output type).
* Can modify `self` (e.g., update instance counters, accumulate history).
```python
# Example: Add a counter to the class for state mutation
# def __init__(self, *args, **kwargs):
# super().__init__(*args, **kwargs)
# self.calls_count = 0
def act(self, input: MyInput, **kwargs) -> MyIntermediate:
# self.calls_count += 1 # Example of state mutation
processed_text = input.text.strip().lower()
# Example: simple entity "extraction"
entities = [word for word in processed_text.split() if len(word) > 5]
return MyIntermediate(processed_text=processed_text, entities_found=entities)
```
### 6. The `post(self, output: MyOutput) -> bool` Method
This method defines the post-conditions. It's called by `_validate_output` with an instance of the `forward` method's declared return type (e.g., `MyOutput`). This instance is typically generated by an LLM call within `_validate_output` based on your class's `prompt` and the (potentially `act`-modified) input.
* **Signature**: `def post(self, output: YourOutputModel) -> bool:`
* **Behavior**:
* If all post-conditions are met, `return True`.
* If a post-condition is violated, **raise an exception** with a descriptive message. This message guides LLM self-correction if `post_remedy` is enabled.
```python
def post(self, output: MyOutput) -> bool:
if not output.result:
raise ValueError("The final result string cannot be empty.")
if output.is_valid is False and len(output.result) < 10:
raise ValueError("If result is marked invalid, it should at least have a short explanation (min 10 chars).")
# Example: could use self.custom_threshold modified by act
# if hasattr(self, 'custom_threshold') and output.some_score < self.custom_threshold:
# raise ValueError("Score too low based on dynamic threshold.")
return True
```
### 7. The `forward(self, input: MyInput, **kwargs) -> MyOutput` Method
This is your class's original `forward` method, containing the primary logic. The `@contract` decorator wraps this method.
* **Signature**: `def forward(self, model_input: YourInputModel, **kwargs) -> YourOutputModel:`
* The decorator binds the **first positional or positional-or-keyword parameter after `self`** as the canonical contract input. Naming the parameter `input` is still idiomatic, but any identifier works.
* That parameter must be type-hinted with an `LLMDataModel` subclass (or a Python type that the decorator can wrap dynamically) compatible with your `pre`/`act` expectations.
* The method **must have a return type annotation** (e.g., `-> YourOutputModel`), which must be an `LLMDataModel` subclass. This declared type is crucial for the contract's type validation and output generation phases.
* Calls may use positional or keyword arguments interchangeably; any remaining `**kwargs` are forwarded unchanged to your logic and downstream engines.
* **Behavior**:
* This method is **always called** by the contract's `wrapped_forward` (in its `finally` block), regardless of whether the preceding contract validations (`pre`, `act`, `post`, remedies) succeeded or failed.
* **Developer Responsibility**: Inside your `forward` method, you *must* check `self.contract_successful` and/or `self.contract_result`.
* If `self.contract_successful` is `True`, `self.contract_result` holds the validated (and possibly remedied) output from the contract pipeline. You should typically return this.
* If `self.contract_successful` is `False`, the contract failed. `self.contract_result` might be `None` or an intermediate (invalid) object, and `self.contract_exception` holds the underlying exception from the contract pipeline. In this case, your `forward` method can:
* Return a sensible default object that matches `YourOutputModel`.
* Or, if you prefer to propagate the error, raise it to preserve the original context, e.g.,
```python
raise self.contract_exception or ValueError("Contract failed!")
```
* The argument bound to your first non-`self` parameter (e.g., `model_input`) depends on whether the contract succeeded:
* If `contract_successful == True`: that argument is the `current_input` from `wrapped_forward` which was used by `_validate_output`. This `current_input` is the output of `_act` if `act` is defined, otherwise it's the output of `_validate_input`.
* If `contract_successful == False`: that argument is the `original_input` (the raw value provided to the contract call, after initial type validation by `_is_valid_input` but before `pre` or `act` modifications).
```python
def forward(self, input: MyInput, **kwargs) -> MyOutput:
if not self.contract_successful or self.contract_result is None:
# Contract failed, or result is not set: implement fallback
return MyOutput(result="Error: Processing failed due to contract violation.", is_valid=False)
# Contract succeeded, self.contract_result holds the validated output
# You can do further processing on self.contract_result if needed,
# or simply return it.
final_result: MyOutput = self.contract_result
final_result.result += " (Forward processed)" # Example of further work
return final_result
```
#### Input Binding Rules
The contract wrapper now resolves the canonical input value without requiring an `input=` keyword argument. The resolution order is:
1. The first positional argument supplied when you call the contracted instance (i.e., `my_expr(my_input)`).
2. If no positional value is provided, the first positional-or-keyword parameter defined after `self` in your `forward` signature (for example, `model_input`) is fetched from `**kwargs`.
3. As a backwards-compatible fallback, an explicit `input=` keyword argument is still accepted.
The resolved object is then passed consistently through `_is_valid_input`, `pre`, `act`, `_validate_output`, and finally your original `forward` method. All remaining keyword arguments are forwarded untouched.
#### Error Handling and Propagation
When a contract validation or remediation step fails, the exception is captured in `self.contract_exception`, and `self.contract_successful` is set to `False`. If you prefer to surface these errors instead of returning fallback values, you can propagate the exception in your `forward` implementation:
```python
def forward(self, input: MyInput, **kwargs) -> MyOutput:
if self.contract_result is None:
# Propagate the original contract exception, or a generic one
raise self.contract_exception or ValueError("Contract failed!")
return self.contract_result
```
```python
# Example: graceful=True → suppressed errors, skip type check (can return any type)
# Contract decorator configured as:
# @contract(pre_remedy=False, post_remedy=True, remedy_retry_params={"graceful": True, ...})
class MyExpr(Expression):
def forward(self, input: MyInput, **kwargs) -> MyOutput:
# In graceful mode, contract_exception is None on failures,
# and the final output type check is skipped.
# You may return a completely different type than the annotation.
if not self.contract_successful or self.contract_result is None:
# Fallback logic returning a raw dict instead of MyOutput
return {
"status": "error",
"message": "Fallback allowed under graceful mode"
}
# On success, return the validated contract result
return self.contract_result
```
### Ensuring Meaningful Output: The Importance of `pre` and `post` Conditions
It's quite easy to end up with a meaningless, "gibberish" object if you never really validate its contents. The role of `pre` and `post` conditions is exactly that: to ensure not just the shape but also the substance of your data.
Before, the system might have returned a dummy filler object by default, even before the prompt was passed into the type-validation function. Now, while the prompt is wired through that function and the object should populate more sensibly, a core principle remains:
> If the `post` method doesn't fail – either because no `ValueError` was thrown or because you skipped all semantic checks (e.g., by simply having `post` return `True`) – the contract will happily hand you back whatever came out of the type-validation step.
Since the `TypeValidationFunction` (which handles the type-validation step) primarily enforces "is this a valid instance of the target type?" and doesn't inherently care what the fields contain beyond basic type conformance, you might get dummy values or inadequately populated fields unless you specify richer constraints.
So, if your `LLMDataModel` types lack meaningful `Field(description="...")` attributes and your `prompt` isn't explicit enough, you might just get randomness or minimally populated objects. This is expected behavior. The contract pattern isn't broken; it's doing exactly what you told it to: validate shape, and substance *only if you explicitly define checks for it*.
To illustrate, say you want a non-trivial `title: str` in your output object, but you never write a `post` check to validate its content (e.g., `if not output.title or len(output.title) < 10: raise ValueError("Title is missing or too short")`). In such a case, you might keep receiving a placeholder string or an inadequately generated title. While passing the main prompt into the `TypeValidationFunction` helps it try to generate something relevant, without a `post`-condition to enforce your specific requirements, you might still see undesirable behavior.
**In short: the contract pattern is doing its job. If you want substance, you must codify those semantic rules in your `LLMDataModel` field descriptions and, critically, in your `pre` and `post` validation checks.**
## Contract Execution Flow
When you call an instance of your contracted class (e.g., `my_instance(my_input_data)` or `my_instance(input=my_input_data)`), the `wrapped_forward` method (created by the `@contract` decorator) executes the following sequence:
1. **Return Type Annotation Validation & Dynamic Wrapping (`_is_valid_output` + `_try_dynamic_type_annotation`)**:
* Inspects your `forward` method's return type annotation (`sig.return_annotation`).
* Ensures you provided a return type annotation and it’s a subclass of `LLMDataModel`.
* If the annotation is a native Python/typing type (e.g., `str`, `list[int]`, `Optional[...]`), the system automatically builds a dynamic `LLMDataModel` wrapper for the output type, allowing subsequent validation and unwrapping.
2. **Initial Input Collection & Dynamic Wrapping (`_is_valid_input` + `_try_dynamic_type_annotation`)**:
* Determines the canonical contract input by prioritizing the first positional argument after `self`. If no positional value is provided, it falls back to the first compatible keyword (preferring the corresponding parameter name, then `input` for backward compatibility).
* Validates that canonical value with `_is_valid_input` and stores it as `original_input`.
* If the value is a native Python type (and not already an `LLMDataModel`), the system inspects your `forward` signature to infer the expected Python type and automatically wraps your primitive or container in a temporary `LLMDataModel` for validation (via `_try_dynamic_type_annotation`).
3. **Pre-condition Validation (`_validate_input`)**:
* The `current_input` (initially `original_input`) is passed to your `pre(input)` method.
* If `pre()` raises an exception and `pre_remedy=True`, `SemanticValidationFunction` attempts to correct the `current_input` based on the exception message from `pre()` and your class's `prompt`.
* If `pre()` raises and `pre_remedy=False` (or remedy fails), an `Exception("Pre-condition validation failed!")` is raised (this exception is then handled by `wrapped_forward`'s main `try...except` block).
4. **Intermediate Action (`_act`)**:
* If your class defines an `act` method:
* Its signature is validated to ensure the first positional (or positional-or-keyword) parameter after `self` is type-hinted, and the return annotation is present.
* `act(current_input, **act_kwargs)` is called. `current_input` here is the output from the pre-condition validation step.
* The result of `act` becomes the new `current_input`.
* The actual type of `act`'s return value is checked against its annotation.
* If no `act` method, `current_input` remains unchanged.
5. **Output Validation & Generation (`_validate_output`)**:
* This is a critical step, especially when `post_remedy=True`.
* It uses `TypeValidationFunction` and (if `post_remedy=True`) `SemanticValidationFunction`.
* The goal is to produce an object that matches your `forward` method's return type annotation (e.g., `MyOutput`).
* The `current_input` (which is the output from `_act`, or from `_validate_input` if no `act`) and your class's `prompt` are used to guide an LLM call to generate/validate data conforming to the target output type.
* Your `post(output)` method is called with the LLM-generated/validated output object.
* If `post()` raises an exception and `post_remedy=True`, remediation is attempted.
* If your `forward` return annotation is a native Python type or typing construct (e.g., `int`, `list[str]`, `dict[str, int]`, `Optional[...]`, `Union[...]`), the contract will build a dynamic `LLMDataModel` wrapper for the output, validate and (if needed) remediate it, then automatically unwrap and return the native value on exit.
* If all these steps (type validation, LLM generation, `post` validation, remedies) succeed:
* `self.contract_successful` is set to `True`.
* `self.contract_result` is set to the final, validated output object.
* This output is typically assigned to `final_output` within the `try` block of `wrapped_forward` (the method created by the decorator).
6. **Exception Handling in Main Path (`wrapped_forward`'s `try...except`)**:
* Steps 2, 3, and 4 (pre-validation, act, and output validation/generation) are wrapped in a `try...except Exception as e:` block within the decorator's logic.
* If any exception occurs during these steps (e.g., an unrecoverable failure in `_validate_input`, `_act`, or `_validate_output`), the `logger` records it, and `self.contract_successful` is set to `False`.
7. **Final Execution (`finally` block of `wrapped_forward`)**:
* This block **always executes**, regardless of success or failure in the preceding `try` block.
* It determines the `forward_input` for your original `forward` method:
* If `self.contract_successful` is `True`, `forward_input` is the `current_input` that successfully passed through `_act` and was used by `_validate_output`.
* If `self.contract_successful` is `False`, `forward_input` is the `original_input`.
* Your class's original `forward` method is invoked with that canonical input reinserted (as the first positional argument or matching keyword) alongside the untouched auxiliary `**kwargs`.
* The value returned by *your* `forward` method becomes the ultimate return value of the contract call.
* A final output type check is performed on this returned value against your `forward` method's declared return type annotation. If the contract is configured with `graceful=True`, this final type check is skipped instead of raising a `TypeError`.
## Example
This is a 0-shot example generated by o3 from the above documentation and tests.
```python
# ──────────────────────────────────────────────────────────────
# Standard library │
# ──────────────────────────────────────────────────────────────
from typing import List, Optional
from pydantic import Field
# ──────────────────────────────────────────────────────────────
# SymbolicAI core │
# ──────────────────────────────────────────────────────────────
from symai import Expression # Base class for your LLM “operators”
from symai.models import LLMDataModel # Thin Pydantic wrapper w/ LLM hints
from symai.strategy import contract # The Design-by-Contract decorator
# ▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
# 1. Data models ▬
# – clear structure + rich Field descriptions power ▬
# validation, automatic prompt templating & remedies ▬
# ▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
class Document(LLMDataModel):
"""Represents an entire document in the tiny in-memory corpus."""
id: str = Field(description="Unique identifier of the document.")
content: str = Field(description="The full raw text of the document.")
class DocSnippet(LLMDataModel):
"""
Exact passage taken *verbatim* from a Document.
We store the `doc_id` so the answer can cite its source.
"""
doc_id: str = Field(description="ID of the document the snippet comes from.")
snippet: str = Field(description="A short excerpt supporting the answer.")
class MultiDocQAInput(LLMDataModel):
"""
The *input* to the contract call:
• the user’s natural-language question
• the corpus it may answer from
• a caller-specified upper bound on how many snippets can be cited
"""
query: str = Field(description="User question in plain English.")
documents: List[Document] = Field(description="Corpus to search for answers.")
max_snippets: Optional[int] = Field(
default=3,
ge=1,
le=10,
description="Max number of snippets the agent may cite (defaults to 3).",
)
class IntermediateRetrieved(LLMDataModel):
"""
Returned by `act()`: lightweight retrieval result that will be fed to
the LLM so it can see relevant sentences without scanning whole docs.
"""
query: str = Field(description="The original question from the user.")
top_docs: List[Document] = Field(description="Top-k most relevant documents.")
selected_sentences: List[str] = Field(
description="Sentences deemed most relevant to the query."
)
target_snippet_count: int = Field(
description="Upper bound on evidence snippets (copied from input)."
)
class AnswerWithEvidence(LLMDataModel):
"""
Final object returned to the **caller** (and validated by `post`).
"""
answer: str = Field(description="Concise, stand-alone answer.")
evidence: List[DocSnippet] = Field(description="Cited supporting passages.")
coverage_score: float = Field(
ge=0.0,
le=1.0,
description=(
"LLM-estimated fraction of answer that is directly supported by the "
"evidence (0 = no support, 1 = fully supported)."
),
)
# ▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
# 2. The contracted class ▬
# ▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
@contract(
# ── Remedies ─────────────────────────────────────────── #
pre_remedy=True, # Try to fix bad inputs automatically
post_remedy=True, # Try to fix bad LLM outputs automatically
accumulate_errors=True, # Feed history of errors to each retry
verbose=True, # Log internal steps (see `symai.strategy` logger)
remedy_retry_params=dict(tries=3, delay=0.4, max_delay=4.0,
jitter=0.15, backoff=1.8, graceful=False),
)
class MultiDocQAgent(Expression):
"""
High-level behaviour:
1. `pre` – sanity-check query & docs
2. `act` – *retrieve* relevant sentences, mutate state
3. LLM – generate AnswerWithEvidence (handled by SymbolicAI engine)
4. `post` – ensure answer & evidence meet semantic rules
5. `forward`
• if contract succeeded → return type validated LLM object
• else → graceful fallback answer
"""
# ───────────────────────── init ───────────────────────── #
def __init__(self, min_coverage: float = 0.55, *args, **kwargs):
super().__init__(*args, **kwargs)
self.min_coverage = min_coverage # threshold for `post`
self.interaction_log: list[dict] = [] # keeps a history of queries
# ───────────────────────── prompt ─────────────────────── #
@property
def prompt(self) -> str:
"""
A *static* description of what the LLM must do.
Braces {{like_this}} will be replaced with fields from
the object produced by `_validate_input`/`_act`.
"""
return (
"You are an expert research assistant.\n"
"Given a QUESTION and a set of RELEVANT_SENTENCES, write a concise "
"answer. Cite every passage you use exactly as `(Doc )`. "
"Respond with a JSON object that fits the AnswerWithEvidence schema."
)
# ───────────────────────── pre ────────────────────────── #
def pre(self, input: MultiDocQAInput) -> bool:
"""
Guard-clauses before we even *touch* the LLM.
Raise ValueError with human-readable messages – they become corrective
prompts if `pre_remedy=True`.
"""
if not input.query.strip():
raise ValueError("The query must not be empty.")
if not input.documents:
raise ValueError("You must supply at least one document.")
return True # all good
# ───────────────────────── act ────────────────────────── #
def act(self, input: MultiDocQAInput, **kwargs) -> IntermediateRetrieved:
"""
Lightweight pseudo-retrieval.
Steps:
• score each doc by term overlap with the query
• keep top-k (k ≤ 3)
• within each, take two most overlapping sentences
• log the interaction for later analytics
"""
k = min(3, len(input.documents))
query_terms = {t.lower() for t in input.query.split()}
# Score documents by *crude* term overlap
scored_docs = []
for doc in input.documents:
overlap = sum(t in query_terms for t in doc.content.lower().split())
scored_docs.append((overlap, doc))
scored_docs.sort(reverse=True, key=lambda x: x[0])
top_docs = [doc for _, doc in scored_docs[:k]]
# Extract at most 2 high-overlap sentences from each top doc
selected_sentences: list[str] = []
for doc in top_docs:
sentences = [s.strip() for s in doc.content.split(".") if s.strip()]
sentences.sort(
reverse=True,
key=lambda s: sum(t in query_terms for t in s.lower().split()),
)
selected_sentences.extend(sentences[:2])
# Record what we did (just for analytics / debugging)
self.interaction_log.append(
{
"query": input.query,
"num_docs": len(input.documents),
"top_doc_ids": [d.id for d in top_docs],
}
)
# Return a *different* LLMDataModel; this becomes the
# `current_input` for the output-validation phase.
return IntermediateRetrieved(
query=input.query,
top_docs=top_docs,
selected_sentences=selected_sentences,
target_snippet_count=input.max_snippets or 3,
)
# ───────────────────────── post ───────────────────────── #
def post(self, output: AnswerWithEvidence) -> bool:
"""
Semantic guarantees:
• non-empty answer
• coverage ≥ threshold
• high-coverage → must actually cite evidence
• evidence list ≤ `target_snippet_count` learned in `act`
Any violation ⇒ raise ValueError (triggers post-remedy or failure).
"""
if not output.answer.strip():
raise ValueError("Answer text is empty.")
# coverage gate
if output.coverage_score < self.min_coverage:
raise ValueError(
f"Coverage score {output.coverage_score:.2f} "
f"is below the minimum {self.min_coverage:.2f}."
)
# If it claims high coverage but provides no evidence, that's fishy
if output.coverage_score >= 0.8 and not output.evidence:
raise ValueError(
"High coverage claims require at least one evidence snippet."
)
# Enforce caller’s snippet bound (act stored it on self._current_input)
max_allowed = getattr(self, "_current_input", None)
if (
isinstance(max_allowed, IntermediateRetrieved)
and output.evidence
and len(output.evidence) > max_allowed.target_snippet_count
):
raise ValueError(
f"Too many snippets ({len(output.evidence)}), "
f"maximum allowed is {max_allowed.target_snippet_count}."
)
return True # all checks passed
# ───────────────────────── forward ────────────────────── #
def forward(self, input: MultiDocQAInput, **kwargs) -> AnswerWithEvidence:
"""
ALWAYS executed (even if contract failed).
Success path → return the LLM-validated object (`self.contract_result`)
Failure path → build a polite fallback answer that still matches schema
"""
# ── happy path ─────────────────────────────────────── #
if self.contract_successful and self.contract_result:
return self.contract_result
# ── fallback (contract failed) ─────────────────────── #
first_doc = input.documents[0]
first_sentence = first_doc.content.split(".")[0][:300] # keep it short
return AnswerWithEvidence(
answer=(
"I’m not confident enough to answer precisely. "
"Please re-phrase the question or provide more documents."
),
evidence=[DocSnippet(doc_id=first_doc.id, snippet=first_sentence)],
coverage_score=0.0,
)
if __name__ == "__main__":
# ▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
# 3. Mini-demo (only executed when you run the file directly) ▬
# ▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
# ── tiny “corpus” ─────────────────────────────────────── #
docs = [
Document(
id="A1",
content=(
"Symbolic AI combines formal logic with modern machine learning. "
"It allows transparent reasoning and explicit knowledge "
"representation while still benefiting from statistical models."
),
),
Document(
id="B2",
content=(
"Vector databases store embeddings of documents. They let users "
"quickly retrieve text that is semantically similar to a query "
"vector, enabling high-quality semantic search."
),
),
Document(
id="C3",
content=(
"Hybrid search merges sparse keyword techniques and dense vector "
"similarity, improving recall and precision, especially for "
"domain-specific collections."
),
),
]
# ── create agent instance ─────────────────────────────── #
agent = MultiDocQAgent(min_coverage=0.6)
# ── ask a question ────────────────────────────────────── #
question = "Why are vector databases useful for semantic search?"
result = agent(
input=MultiDocQAInput(
query=question,
documents=docs,
max_snippets=2, # caller sets stricter evidence limit
)
)
# ── result ───────────────────────––––––––––––––––––––––– #
print("\nAnswer:\n", result.answer)
print("\nCoverage:", result.coverage_score)
print("\nEvidence:")
for ev in result.evidence:
print(f" • (Doc {ev.doc_id}) {ev.snippet}")
agent.contract_perf_stats();
```